自己作为后端研发工程师,一直在公司电商项目中参与和检索相关的工作。工作的时间也不短了,一直希望能写一些文章来总结、整理下自己接触到的知识点,一方面是为了梳理自己的思路,另一方面也作为一种分享和交流。
本文简单总结一下,电商检索系统需要向用户提供哪些功能。
搜索页面结构
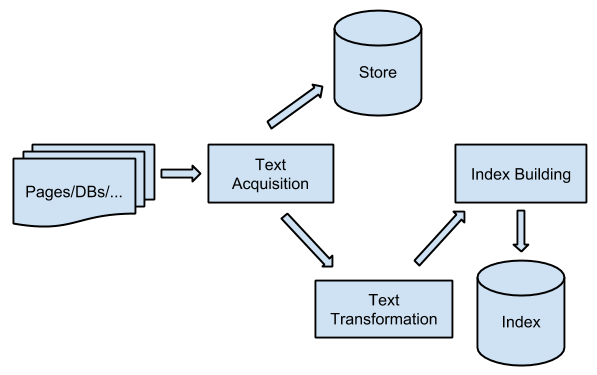
下图是一个电商搜索结果页的基本结构:

大家可以看到,页面基本上有以下几种元素构成:
- 搜索栏
- 商品列表
- 面包屑
- 分类树
- 筛选项
- 商品推荐
每一种元素,都为用户展现了不同纬度的检索结果;同时,部分元素也为用户提供了进一步的检索、过滤功能。
搜索栏,提供了query检索的功能,用户最常用的寻找商品的方式;
分类树和面包屑,一方面从分类纬度展示了搜索结果,同时用户也可以对于上面的结果进行分类检索;
筛选项,提供了对于检索出的商品属性的聚合,同时用户又可以对于自己感兴趣的属性进行单独筛选;
商品列表,是呈现给用户的最终结果;
商品推荐,除了自然的检索结果,还会根据用户当前的检索行为以及历史行为,进行商品推荐。
功能
上面提到的元素,都是为了让用户使用电商检索系统的某些功能,或者向用户展现某些功能的最终结果。下面就具体讲一下电商检索系统需要具备的基本功能:
Query检索
即关键词检索,用户通过输入一个检索词来描述自己的需求,比如“iphone5s”、“三星Galaxy”、“Nike运动鞋”等等。关键词检索,涉及到建立一个检索系统的一些基本步骤:
- 切词(将一段文本转化为一个一个单元,即term)
- 建立倒排索引(Inverted Index)
- 索引归并
- 排序
切词之前,首先需要确定的是:商品的哪些字段需要被切词并且建入索引。商品的标题是需要建索引的,另外,一般来说,商品的品牌名称、商家名称、分类名也是需要建索引。选择建索引字段的范围,其实是需要一些权衡的,范围选得过大,当然可以提高召回率,但这样也会出现一些bad case(比如将商品描述中一些不相关的term建进了索引),同时倒排拉链过长也会影响性能。
分类检索
一般来说,综合型电商网站的首页,都会有一个分类树全集,供用户直接点击查询。例如下图:

除了Query检索,用户按照商品的分类进行检索的比例也会较大。分类检索和Query检索相比,不同点只是少了切词步骤,另外将term改为商品的分类ID。
说到分类,就要涉及到分类体系。一般来说,有两种分类体系:后端分类体系,和前端分类体系。后端分类体系相对稳定,几乎不变,用户感知不到后端分类;前端分类体系结构可以很灵活,随意变化,一般由运营同学来维护。前、后端分类体系都是树状的结构,而后端分类树的任意节点可以“挂载”至一个或者多个前端分类树的叶子节点上面,这样两套分类体系之间就产生了关联。
这两个分类体系可以类比为超市的货物分类(严格来说应该是电商参考了零售行业的分类方式),一开始货物都是放在后台的库房里面的,它们按照一种分类体系(后端分类系统)来存放,非工作人员是看不到的;而等到货物需要从库房摆放到货架时,超市工作人员可以以时令、促销活动等为依据,让货架上的商品按照另一种体系(前端分类体系)进行组织,顾客只能看到这种组织形式。
排序
用户通过query或者分类检索出的商品结果,默认都是按照相关性排序的。(关于相关性排序,内容还是比较复杂的,另外自己也不是专门做这一块的,这里就不展开讲了)除了按照相关性进行排序,用户还可以按照其它条件进行排序,例如:
- 价格
- 折扣
- 评论数
- 好评度
- 上架时间
- 是否正在促销
- ……
上面都是用户可以看得到、自己可以选择的排序方式。除了这些,还会有一些其它因素影响商品结果的排序。
首先是一些基本的业务逻辑,比如在自然排序下,有库存的商品排在前面,无库存的排在后面;SPU商品排在前面,SKU商品排在后面。(SKU、SPU的概念后面会讲到)
另外还有一些运营方面的考虑。比如,发现搜索结果中有一个很不相关的商品出现,这时就急需在query粒度上对这个商品进行打压、甚至是不允许展现。或者,由于某种合作关系,在某些query或者分类下,必须将某个商家的商品排在前面。因此,检索系统后台就需要维护这么一份各个维度的商品“黑白名单”。
标签聚合
所谓标签,就是用一些“键-值”的概念来描述一个商品的特点。比如说MacBookPro,可以有如下标签:
- 品牌:Apple
- 尺寸:13寸
- 处理器:Intel i7
- 价格:9288 RMB
- ……
当用户检索商品时,检索系统除了直接展示商品以外,还会将商品上面的标签进行聚合,一般都是通过“标签名 + 标签值的列表”的形式展现给用户(如下图),方便用户通过标签进行进一步的筛选。

分类树
当用户进行query检索时,检索系统会进行query分析,将这个query可能对应的分类,通过分类树的形式展现给用户。比如用户搜索“小米”,query分析出的分类既有“手机通讯”,又有“粮油米面”。

一般来说,检索系统为了保证query的准确率,会在检索条件中添加query的预测分类,使得检索结果不至于各种分类的商品混杂在一起,影响用户体验。所以当用户搜索“小米”时,检索结果会限定在“手机通讯”这个分类下,但是如果用户真的是想搜索“粮油米面”下的小米,也没关系,只需在点击分类树中相应分类进行限定即可。
面包屑
面包屑,原来是用于在网站上面显示当前页面在整个sitemap中的位置,方便用户跳转至网站其它地方。在电商网站中,就变成了展现网站所在的分类路径( + 品牌名称 + query),例如
电脑、办公 > 电脑整机 > 笔记本 > 清华同方(THTF) > 清华同方锋锐T200
点击面包屑上面的每一级分类,就可以在某个分类下进行商品检索,方便用户扩大或者缩小检索范围。
过滤
除了进行各种触发(query检索、分类检索等),还需要在触发结果的基础上面,再进行过滤。上面说到的标签过滤、分类树限定,都属于过滤。总结下来,会有这么几种过滤方式:
- 分类过滤
- 标签过滤
- 价格区间过滤
- 地域过滤
- 库存过滤
- 是否自营
- 商家过滤(针对于微购这样的电商平台)
Query提示
所谓query提示,就是当用户在搜索框中建入query时,系统能提供给用户一个query list,或者一些分类建议,方便用户向检索系统提供给准确的query以及分类范围,减少用户进行重复搜索的次数。
以下是京东的query提示截屏,有拼音翻译为query、有分类预测、有每个query对应的检索商品数,做的比较完善。

相对而言,微购做的query提示就原始许多,输入“shouji”,居然连本身的“手机”都没有,囧……

Query改写
Query分析中的一项功能就是做“query correction”,通过算法或者人工标注的形式,判断出用户真正需要搜索的query是什么。比如用户输入了“按着手机”,检索系统需要能判断出用户搜索的真正query可能是“安卓手机”,当然,好的产品肯定能让用户自行选择,而不是强奸用户,就像上面提到的用户可以选择分类树上的分类,用以明确告知系统自己所需要查找的分类范围。
以下是在京东搜索“按着手机”的截图:

SPU聚合
首先需要提供两个概念:SKU,以及SPU。
根据我在网上查找到的资料,SKU是Stock Keeping Unit,指的是库存的最小单位;而SPU是Standard Product Unit,是指商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。
简单的理解就是,“iPhone4S”是一个SPU,“iPhone4S 白色 16G 电信版”就是一个SKU;“MacBookPro”是一个SPU,“MacBookPro 13寸 8G内存 128G硬盘”就是一个SKU。
因此,当用户进行商品检索时,需要将SKU粒度的商品聚合成SPU粒度,使得检索结果比较多样,从而不至于满屏都是各种颜色、型号的同一款商品。等到用户进行商品详情页之后,再来选择具体的型号。
下图是微购检索结果页SPU、SKU排列结果:

以下是京东商品详情页的截屏,红框中的选项的每一种组合,都代表着不同的SKU。

推荐
推荐系统,是和检索系统同样负责的系统,另外我也并不熟悉相关的知识,所以这里只是根据自己的理解,简单的说一下。
从页面角度来说,几乎所有页面上面都可以进行商品推荐:首页、搜索结果页、详情页、购物车页面、下单成功页、错误页,等等。而不同的页面,推荐的侧重点也会不尽相同。
比如首页推荐,用户这次购物流程还没有任何行为,所以一般都是通过该用户的历史行为向用户进行推荐。
在详情页,用户则已经表现出对于这个商品的较强的需求,一般会有两种类型的推荐:
- 推荐和该商品类似的商品
- 推荐可以和该商品进行组合的商品
第一种推荐,在各分类商品中出现的都比较多,一般的推荐理由是“看(购买)过该商品的用户也看(购买)了”;

第二种推荐,一般出现在数码产品中。比如用户在看一款手机时,向用户推荐手机套、手机耳机、SD卡,让用户可以“一页式”完成许多商品的购买,减少用户决策的过程,激发用户的购物欲望(原来根本没想到手机套这回事,既然你推荐了,又不贵,就买一个呗)。

到了购物车页面,用户的购物流程即将结束,能让用户在这个阶段再购买的一个主要动力是:凑单,这样可以节省运费或者参加活动。所以在这个阶段推荐的商品一般是:同店铺的相似商品,以及一些单价较低的、日常消费的商品。
总结
本文并没有讲解与电商检索相关的技术细节,只是单独从产品的角度,罗列了一下一个电商检索系统需要具备的功能,只能算是自己粗浅的整理和归纳,肯定有许多遗漏或者错误之处。有问题的话,欢迎大家反馈,我也会及时进行更正。以后有机会的话,还会对电商检索系统中的技术细节进行一些归纳和整理。
— EOF —