对于一个典型的搜索引擎,至少包含两大部分:1)建立索引;2)query查询。
建立索引
主要流程如下图所示:
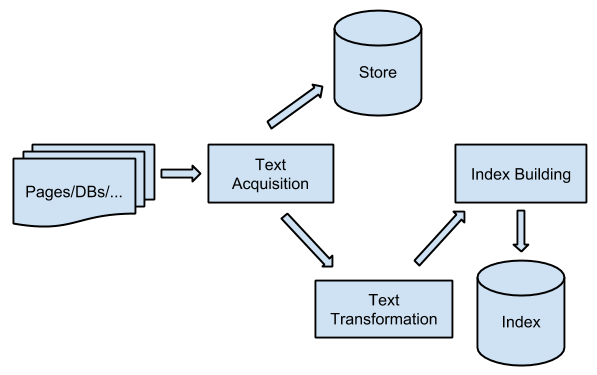
主要工作为:获取需要检索的数据,将其转化为系统可以识别的方式,做一些预处理,最后持久化存储起来。
本文获取 (Text Accquisition)
爬虫
本文获取就是将所需要的数据“抓”下来。其中,依据搜索引擎的使用场景不同(网站内部检索/全网检索/文件系统检索/…),需要检索的数据可以是全网、某个网站的网页、数据库的表、或者磁盘上面的文件等等,这样就需要不同类型的“爬虫”。另外,也可以像RSS这样的流式访问数据的标准。
获取到所需要的数据,这只完成了一部分。另外,当数据源有更新时(网页修改/数据库新增了数据/…),爬虫需要能及时的感知并且重新抓取数据提供给检索系统。而且,不同类型的数据,对于实时性的要求是不一样的。比如,一个发布新闻网站和和一个保存历史资料的网站,它们网页的实时性要求肯定是不一样的。
转换
文本获取到了,需要将其统一成搜索引擎可以识别的格式,文本转换包含两层含义:
- 将不同格式标准的数据转换为统一的格式
例如,同样的记录书籍内容的文档,一个是XML格式的,一个是JSON格式的。爬虫如果想获取书籍的名称、作者、ISBN等信息,就需要采用不同的解析方式。
- 将不同编码的文本转化为统一编码
有的网页是UTF-8编码的,有的是GB18030编码的,都需要统一成一个编码。
存储
数据(数据本身以及MetaData)获取到了,也转成统一格式了,下面就得想办法把数据持久化。持久化的方式有很多种,比如可以是本地文件系统、分布式文件系统(HDFS)、各种数据库(MYSQL / MongoDB)等等。
文本变形 (Text Transformation)
切词 && 归一化
检索索引之前,需要先将文本转化为一系列的term,term可以理解为有意义的最小单位词语,比如:
GitHub is the best place to share code with friends, co-workers, classmates, and complete strangers.
就会生成github, best, place, share, code, friend, co-worker, classmate, complete, stranger这些term。其中会将is, the等没有实际意义的单词去掉,然后做归一化,比如大小写转换,单复数转换等。
中文一句话中没有空格表示停顿,转化term会更复杂,比如上学时老师举的一个例子:
南京市长江大桥
应该需要切成南京市, 长江以及大桥,而不是南京, 市长, 江大桥
质量度
除了获取已经归一化的、数据所需要表达的信息之外,还需要对这份数据本身的质量做一个判断,相当于一个小网站发布的新闻和一个大网站发布的新闻,按照常理明显后者的质量、可信度等因素要优化前者。(在某些国家,事实真的是这样吗? :P )。PageRank算法就是一个例子,采用迭代的方式,通过网页链接(也就是网页的出度和入度)来计算该网页的质量度。
构建索引
一般来说,倒排索引的结构是这样的:
term1 -> (docid_1, data_11), (docid_2, data_12), ...
term2 -> (docid_2, data_21), (docid_3, data_22), ...
其中,term就是某一个切词的结果的签名,当然,这里的term也可以是其它信息,比如商品的分类、文章的类型等等。其实应用中需要什么样的触发方式,就可以建立对应类型的倒排。docid就是用来唯一标识一份数据的,数据可以是一个网页、一个商品等等,一般都会称其Document。至于data,主要是为计算doc相对于term的权重服务的,里面存储了计算权重所需要的数据。举个简单的例子,如果我们假设一篇文章中出现某个term的次数越多,这篇文章对于这个term就越相关,这时候在data数据里面存储这个term在该文章中出现的次数即可。另外,有些权重计算在建立索引的阶段就可以完成,因此这部分权重结果也会存放在data中。
所以,建立倒排索引的第一步,就是扫描整个数据全集,收集有关term和document的统计信息(term在doc中出现的频率,term在整个doc全集中出现的频率,term的偏移量,doc的更新时间,etc.)。接着,将数据集合,由doc -> (term1, term2, term3, ...)转化为term -> (doc1, doc2, doc3, ...)的倒排形式,其中包含了对term以及doc的权重计算。最后,将倒排索引dump出来,有时出于数据量和性能的考虑,还需要将索引分库存储,分库方式有两种:按document分库,以及按term进行分库。
Query查询
query查询的主要步骤如下图所示:
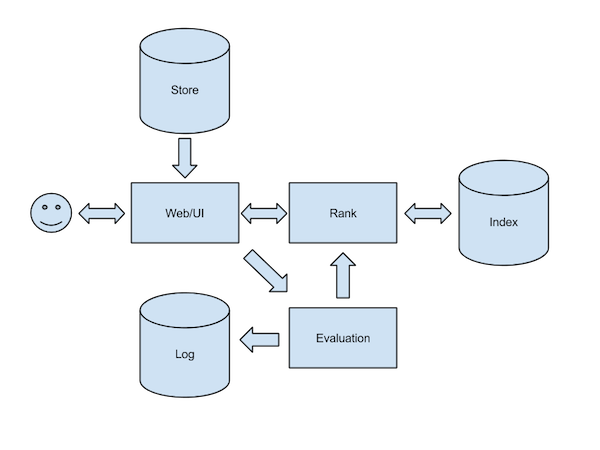
User Interface
对于用户来说,直接面对的是搜索引擎的Web界面,或者说是User Interface界面。UI有以下几个功能:
- 接收用户输入,将其转化为一棵query查询树,作为排序模块的输入。query查询树节点上面的操作一般是
AND/OR/NOT这样的布尔运算; - 进行query变换。比如拼写检查、query推荐、query扩展;
- 展现最终的排序结果。包括:填充document信息(物料)、生成内容摘要、对关键信息进行飘红或者加粗等等。
排序
排序模块决定了结果文档集合的先后顺序,文档的权重计算方法有很多种,最原始的形式可以表示成:
Sum(qi * di)
其中,qi表示输入query的第i个term的权重,di表示该document相对于第i个term的权重。
qi以及di权重的计算,一般是基于tf.idf的思想。tf(term frequency),表示term在document或者query中出现的频率;而idf(inverse document frequncy),则是term出现在整个document或者query全局中的频率的倒数。这种思想其实很好理解,如果一个词在一篇文章中出现了许多次,我们可以暂且认为这个词和这篇文章是相关的,但是,如果这个词在所有文章中出现的频率都很高,那么这个词就对于那篇文章来说就没有那么“特殊”了,并不能表明这个词和那篇文章就是很相关的。
评估
两层含义:
- 排序相关性的评估
- 性能的评估
通过算法,最终得到一份排序结果,但是由于算法的局限性、训练数据集合是否完备以及个性化等因素,用户并不一定就对排在前面的结果感兴趣。因此,需要一个评估模块,收集用户的点击行为,用于扩充算法训练数据集合,或者作为算法参数调整的依据,最终反映在排序模块中。
另一方面,搜索引擎的性能,也需要进行监控。通过日志就可以清楚的看到用户的一次检索,各个模块的耗时是多少,哪个模块是性能瓶颈,开发者可以有针对性的进行优化。在测试环节,QA也可以使用日志来反向构造请求,模拟线上请求。
(PS: 文章包含了自己的理解,可能不正确)
— EOF —